SkierEvans wrote: but am confused as to how Resolve compares with CUDA for NVIDIA or OpenCL for AMD.
Hi.
nVidea changed the ALUs ( Calculator circuit ) on the RTX 3080 Serie compared to the RTX 2080 Ti Serie and cards before.
There are still 64 pure Floating Point FP32 ALUs per SM, but instead of the 64 pure Integer INT32 ALUs, there are now 64 NEW ALUs, which can perform Floating Point and Integer calculations. But not at the same time.
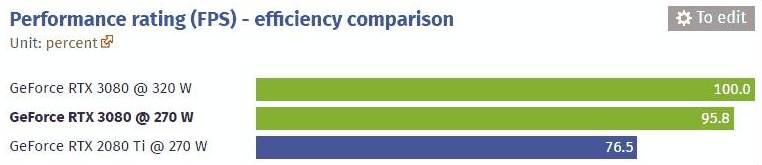
A RTX 2080 Ti SM can therefore perform a maximum of 64 FP32 and 64 INT32 calculations at the same time. An RTX 3080 SM, on the other hand, either 128 FP32 or 64 FP32 and 64 INT32 calculations
depending on the workload, Resolve is sending to the graphics card.
If a PC Application only is using its RTX 3080 Graphics Card for Floating Point FP32 calculations using CUDA. Is the performance 29768 GFLOPS.
But if a PC Application only is using its RTX 3080 Graphics Card for 50% Floating Point FP32 and 50% of Interger calculation using CUDA. Is the performance 14.884 GFLOPS.
I don't know how the Internal of Resolve is working, but I expect the right answer to be somewhere in between. The best way to find the actual performance, is to check the Resolve Benchmarks for the different Graphics Cards.
In the paid STUDIO Version of Resolve, can certain combination of Codec, Resolutions, Bit width and Chroma subsampling be hardware decoded/encoded on either a AMD or a nVidea Graphics card.
Then you can use a little less powerfull CPU.
Regards Carsten.